© 2026 InterSystems Corporation, Cambridge, MA. All rights reserved.Privacy & TermsGuaranteeSection 508Contest Terms

iris-gaia-dr3 

0
0 reviews
0
Awards
69
Views
0
IPM installs
 1
1 0
0
Details
Releases (1)
Reviews
Issues
Videos (1)
Articles (1)
IoP application for the Gaia DR3 epoch photometry benchmark
What's new in this version
Initial Release
Gaia DR3 Parallel IoP Benchmark
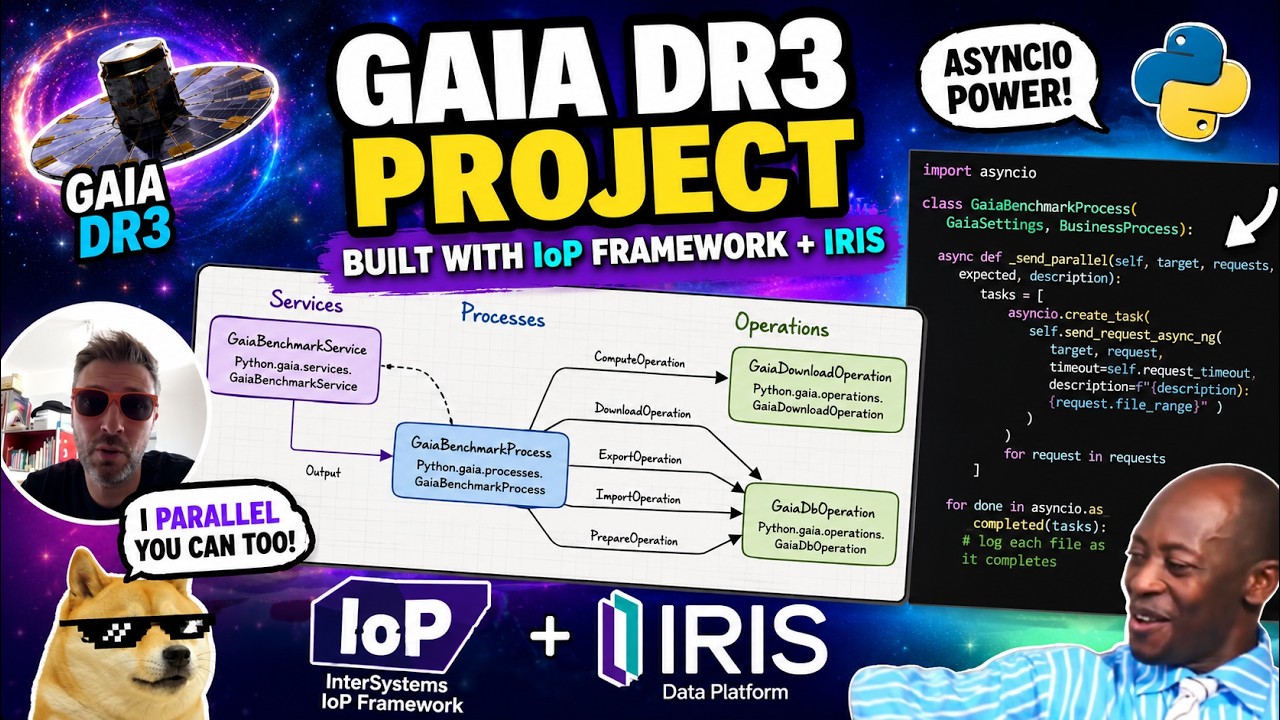
This project is an InterSystems IRIS Interoperability On Python, or IoP, application for the Gaia DR3 epoch photometry benchmark described in https://github.com/grongierisc/iris-gaia-dr3/blob/master/GOAL.md.
It processes the first 20 Gaia DR3 epoch photometry archives, computes BP/RP flux variation by source_id, and writes the qualifying results to output/results.csv with a header row.
Goal
The benchmark asks for every astronomical object whose BP or RP flux changed by more than 100 percent over the observation period.
For each source_id, the application:
- Reads only the first 20 Gaia DR3 epoch photometry files, from
EpochPhotometry_000000-003111.csv.gzthroughEpochPhotometry_020985-021233.csv.gz. - Parses
bp_fluxandrp_fluxarray fields. - Ignores blanks, null-like values,
NaN, infinities, and malformed values. - Computes BP min/max and RP min/max across valid values.
- Computes percentage change as
((max_flux - min_flux) / min_flux) * 100. - Keeps the larger BP/RP percentage change.
- Outputs only rows where
percentage_change > 100.
Output columns:
source_id,bp_min_flux,bp_max_flux,rp_min_flux,rp_max_flux,percentage_change
The CSV starts with that header row, followed by one row per qualifying source_id.
Quick Run
Requirements:
- Docker with Docker Compose
- Network access to the Gaia CDN
Run the benchmark:
./RunChallenge.sh
RunChallenge.sh rebuilds and recreates the IRIS container, starts the IoP production, waits for completion, and prints output/results.csv to stdout.
The generated files are:
output/downloads/*.csv.gz: downloaded Gaia source filesoutput/results.csv: final benchmark outputoutput/results.done: success markeroutput/results.err: failure marker, if the production fails
Local Development
Create and use a virtual environment if one is not already present:
python -m venv .venv
. .venv/bin/activate
pip install -r requirements.txt
Run tests:
.venv/bin/python -m pytest
Validate the IoP production without writing to IRIS:
.venv/bin/iop --migrate https://github.com/grongierisc/iris-gaia-dr3/blob/master/settings.py --dry-run
Run the full Docker workflow:
docker compose up --build
Architecture
The application is an IoP production declared in https://github.com/grongierisc/iris-gaia-dr3/blob/master/settings.py and https://github.com/grongierisc/iris-gaia-dr3/blob/master/gaia/production.py.
Business roles:
GaiaBenchmarkService: polling entrypoint. It starts one benchmark run when neitherresults.donenorresults.errexists.GaiaBenchmarkProcess: orchestrates the workflow and writes success/failure markers.GaiaDownloadOperation: downloads or reuses one local gzip file per request.GaiaDbOperation: owns the IRIS DBAPI connection lifecycle and routes DB work by message type:
prepare run, import aggregate rows, compute final rows, and export the CSV.
IoP Mermaid graph generated from the production object:
flowchart LR
%% Production: GaiaDR3.Production
subgraph group_service["Services"]
direction TB
node_GaiaBenchmarkService["GaiaBenchmarkService
Python.gaia.services.GaiaBenchmarkService"]
end
subgraph group_process["Processes"]
direction TB
node_GaiaBenchmarkProcess["GaiaBenchmarkProcess
Python.gaia.processes.GaiaBenchmarkProcess"]
end
subgraph group_operation["Operations"]
direction TB
node_GaiaDownloadOperation["GaiaDownloadOperation
Python.gaia.operations.GaiaDownloadOperation"]
node_GaiaDbOperation["GaiaDbOperation
Python.gaia.operations.GaiaDbOperation"]
end
node_GaiaBenchmarkService ~~~ node_GaiaBenchmarkProcess
node_GaiaBenchmarkProcess -- "ComputeOperation" --> node_GaiaDbOperation
node_GaiaBenchmarkProcess -- "DownloadOperation" --> node_GaiaDownloadOperation
node_GaiaBenchmarkProcess -- "ExportOperation" --> node_GaiaDbOperation
node_GaiaBenchmarkProcess -- "ImportOperation" --> node_GaiaDbOperation
node_GaiaBenchmarkProcess -- "PrepareOperation" --> node_GaiaDbOperation
node_GaiaBenchmarkService -- "Output" --> node_GaiaBenchmarkProcess
Demo Screenshots
These screenshots show the same production running in the IRIS interoperability UI.
Production

The production screenshot comes from the graph declared in https://github.com/grongierisc/iris-gaia-dr3/blob/master/gaia/production.py.
The code creates one polling service, one orchestrating process, one download operation, and one DB operation.
Several process targets are intentionally routed to the same DB operation so one component owns DBAPI lifecycle.
prod = Production("GaiaDR3.Production", testing_enabled=True, actor_pool_size=actor_pool_size)service = prod.service("GaiaBenchmarkService", GaiaBenchmarkService, settings=gaia_settings) process = prod.process("GaiaBenchmarkProcess", GaiaBenchmarkProcess, settings=gaia_settings) download = prod.operation( "GaiaDownloadOperation", GaiaDownloadOperation, settings=gaia_settings, pool_size=download_pool_size, ) db = prod.operation( "GaiaDbOperation", GaiaDbOperation, settings=gaia_settings, pool_size=import_pool_size, )
service.connect(GaiaBenchmarkService.Output, process) process.connect(GaiaBenchmarkProcess.DownloadOperation, download) process.connect(GaiaBenchmarkProcess.PrepareOperation, db) process.connect(GaiaBenchmarkProcess.ImportOperation, db) process.connect(GaiaBenchmarkProcess.ComputeOperation, db) process.connect(GaiaBenchmarkProcess.ExportOperation, db)
Settings

The settings screenshot shows the Gaia settings exposed on the IoP components.
The typed settings are declared once in https://github.com/grongierisc/iris-gaia-dr3/blob/master/gaia/runtime.py, then https://github.com/grongierisc/iris-gaia-dr3/blob/master/settings.py supplies environment-backed defaults.
class GaiaSettings:
ArchiveUrlTemplate: Annotated[str, Setting(data_type=str, required=True, category="Gaia")]
FileBoundaries: Annotated[str, Setting(data_type=str, required=True, category="Gaia")]
OutputDir: Annotated[str, Setting(data_type=str, required=True, category="Gaia", control=controls.directory())]
RequestTimeoutSeconds: Annotated[int, Setting(data_type=int, required=True, category="Gaia")]
HttpTimeoutSeconds: Annotated[int, Setting(data_type=int, required=True, category="Gaia")]
DbBatchSize: Annotated[int, Setting(data_type=int, required=True, category="Gaia")]
GAIA_SETTINGS = {
"ArchiveUrlTemplate": ARCHIVE_URL_TEMPLATE,
"FileBoundaries": ",".join(FIRST_20_FILE_BOUNDARIES),
"OutputDir": os.getenv("GAIA_OUTPUT_DIR", "/irisdev/app/output"),
"RequestTimeoutSeconds": int(os.getenv("GAIA_REQUEST_TIMEOUT_SECONDS", "1800")),
"HttpTimeoutSeconds": int(os.getenv("GAIA_HTTP_TIMEOUT_SECONDS", "120")),
"DbBatchSize": int(os.getenv("GAIA_DB_BATCH_SIZE", "10000")),
}
Async Traces

The trace screenshot shows the two fan-out phases in https://github.com/grongierisc/iris-gaia-dr3/blob/master/gaia/processes.py.
Prepare, compute, and export are synchronous because they are single sequential steps.
Download and import use send_request_async_ng so the process can log each completed file as soon as its response returns.
downloads = asyncio.run(
self._send_parallel(
self.DownloadOperation,
[
DownloadFileRequest(request.run_name, file_range, self.archive_url(file_range))
for file_range in self.file_ranges
],
DownloadFileResult,
"Download Gaia DR3 files",
)
)
async def _send_parallel(self, target, requests, expected, description: str): tasks = [ asyncio.create_task( self.send_request_async_ng( target, request, timeout=self.request_timeout, description=f"{description}: {request.file_range}", ) ) for request in requests ]results = [] for done in asyncio.as_completed(tasks): result = self._expect(await done, expected, target) results.append(result) self.log_info(f"{description}: {len(results)}/{len(tasks)} {result.file_range}") return results
Workflow
GaiaBenchmarkServicepolls once per second.- It creates
output/results.lockand sends aGaiaBenchmarkRequestto the process. GaiaBenchmarkProcesssendsPrepareRunRequesttoGaiaDbOperationto clear prior persistent rows and output markers.- The process fans out 20
DownloadFileRequestmessages toGaiaDownloadOperationwithsend_request_async_ng. - Downloads are stored in
output/downloads/. Existing readable gzip files are reused. - The process logs each completed download, then fans out 20
ImportFileRequestmessages toGaiaDbOperationwithsend_request_async_ng. - Each import request parses one gzip file, computes per-row BP/RP min/max values, and inserts aggregate rows with
executemany. - The process logs each completed import.
GaiaDbOperationhandlesComputeRequestwith SQL to combine all per-file aggregates bysource_id, calculate percentage change, and persist only results over 100 percent.GaiaDbOperationhandlesExportCsvRequestby selecting final rows ordered bysource_id;gaia.exportingwrites them tooutput/results.csv.- The process writes
output/results.done.
If any step fails, the process writes output/results.err, then re-raises the failure.
Persistent Data
The application uses iris-persistence for class-backed persistent tables:
GaiaDR3.SourceFluxAggregate: per-run, per-file, per-source BP/RP min/max aggregatesGaiaDR3.PhotometryChange: final per-source qualifying results
Persistent indexes:
| Table | Index | Properties | Purpose |
|---|---|---|---|
GaiaDR3.SourceFluxAggregate |
SourceAggregateRunIdx |
run_name |
Delete or scan one benchmark run during preparation and compute. |
GaiaDR3.SourceFluxAggregate |
SourceAggregateSourceIdx |
run_name,source_id |
Group and aggregate per-source rows for a run. |
GaiaDR3.PhotometryChange |
PhotometryChangeRunIdx |
run_name |
Delete or scan final results for one run. |
GaiaDR3.PhotometryChange |
PhotometryChangeSourceIdx |
run_name,source_id |
Read final results ordered by source for export and inspection. |
The application intentionally does not persist every raw observation value. The benchmark output only requires per-source min/max and percentage change, so persisting aggregate rows keeps IRIS storage smaller while preserving the data needed for final SQL analytics.
Downloaded files are persisted on disk under output/downloads/; the presence of a readable gzip file is the download handoff state.
Compute SQL
The compute step uses two persistent tables:
- Source table:
GaiaDR3.SourceFluxAggregate - Change table:
GaiaDR3.PhotometryChange
SourceFluxAggregate is the input to compute. Each row represents one imported source aggregate from one downloaded file:
run_name,file_range,source_id,bp_min_flux,bp_max_flux,rp_min_flux,rp_max_flux
PhotometryChange is the materialized final result table. It stores only rows that satisfy the benchmark rule:
run_name,source_id,bp_min_flux,bp_max_flux,rp_min_flux,rp_max_flux,percentage_change
The compute route in GaiaDbOperation inserts into PhotometryChange with one set-oriented SQL statement:
- Delete prior final rows for the same
run_name. - Read
SourceFluxAggregaterows for thatrun_name. - Group by
source_id. - Compute global min/max BP and RP flux values for each source.
- Compute BP and RP percentage changes.
- Keep the bigger BP/RP change as
percentage_change. - Insert only rows where
percentage_change > 100.
The core grouping is:
SELECT
source_id,
MIN(bp_min_flux) AS bp_min_flux,
MAX(bp_max_flux) AS bp_max_flux,
MIN(rp_min_flux) AS rp_min_flux,
MAX(rp_max_flux) AS rp_max_flux
FROM GaiaDR3.SourceFluxAggregate
WHERE run_name = ?
GROUP BY source_id
Then the compute query applies the benchmark formula:
CASE
WHEN bp_min_flux IS NULL OR bp_min_flux = 0
THEN NULL
ELSE ((bp_max_flux - bp_min_flux) / bp_min_flux) * 100
END AS bp_change
The same logic is applied to RP. The final percentage_change is the larger non-null value between bp_change and rp_change.
Example with one source appearing in multiple files:
| file_range | source_id | bp_min_flux | bp_max_flux | rp_min_flux | rp_max_flux |
|---|---|---|---|---|---|
000000-003111 |
101 |
10 |
20 |
5 |
8 |
003112-005263 |
101 |
7 |
30 |
4 |
9 |
After SQL grouping:
| source_id | bp_min_flux | bp_max_flux | rp_min_flux | rp_max_flux |
|---|---|---|---|---|
101 |
7 |
30 |
4 |
9 |
Percentage changes:
BP = ((30 - 7) / 7) * 100 = 328.5714
RP = ((9 - 4) / 4) * 100 = 125
percentage_change = 328.5714
That row is inserted into PhotometryChange because 328.5714 > 100.
Example where a zero minimum is ignored for one band:
| source_id | bp_min_flux | bp_max_flux | rp_min_flux | rp_max_flux |
|---|---|---|---|---|
202 |
0 |
10 |
4 |
12 |
BP change is NULL because the minimum is zero. RP change is 200, so the final percentage_change is 200.
On the current benchmark dataset, the first 20 Gaia files produced 75064 SourceFluxAggregate rows and 75064 distinct source_id values, so there were no duplicate source_id values across files after import. The SQL still groups by source_id because it is the correct benchmark operation and keeps the production robust if a future dataset contains the same source in multiple files.
SQL is a good fit here because the data is already in IRIS:
- It avoids pulling all aggregate rows back into Python.
- It lets IRIS perform grouping, min/max, filtering, and insertion as one set operation.
- It uses the
run_name,source_idindexes to target one run and organize per-source aggregation. - It materializes final results in
PhotometryChange, making export and inspection simple.
Configuration
Runtime configuration is in https://github.com/grongierisc/iris-gaia-dr3/blob/master/settings.py and is passed to every IoP component as production settings.
Environment overrides:
| Variable | Default | Purpose |
|---|---|---|
GAIA_OUTPUT_DIR |
/irisdev/app/output |
Output directory inside the container |
GAIA_REQUEST_TIMEOUT_SECONDS |
1800 |
Sync request timeout for long-running workflow calls |
GAIA_HTTP_TIMEOUT_SECONDS |
120 |
Per-download HTTP timeout |
GAIA_DB_BATCH_SIZE |
10000 |
DBAPI aggregate insert batch size |
GAIA_ACTOR_POOL |
8 |
Production actor pool size |
GAIA_DOWNLOAD_POOL |
4 |
Download operation pool size |
GAIA_IMPORT_POOL |
4 |
DB operation pool size used by import fan-out |
The 20 benchmark files are configured as compact numeric file boundaries in FIRST_20_FILE_BOUNDARIES; components expand those boundaries into Gaia archive file ranges at runtime.
How It Meets https://github.com/grongierisc/iris-gaia-dr3/blob/master/GOAL.md
- Fully functional:
RunChallenge.shstarts IRIS, runs the production, waits for completion, and prints the CSV result file. - Scalable ingestion: downloads and imports are async fan-out operations with configurable pool sizes and per-file completion logs.
- InterSystems-first implementation: orchestration runs through an IRIS IoP production; aggregate and final result data are stored in IRIS persistent tables.
- Correct dataset:
https://github.com/grongierisc/iris-gaia-dr3/blob/master/settings.pytargets exactly the first 20 Gaia DR3 epoch photometry archives required by the benchmark. - Correct output: final CSV contains
source_id,bp_min_flux,bp_max_flux,rp_min_flux,rp_max_flux,percentage_changeas the header, followed by one object per row. - Correct filtering: SQL persists only rows where the computed maximum BP/RP percentage change is greater than 100.
- Automated execution:
RunChallenge.shis suitable for CI because it requires no manual input and prints only the CSV result file on success.
Verification
Fast local checks:
.venv/bin/python -m pytest
.venv/bin/python -m compileall -q gaia tests https://github.com/grongierisc/iris-gaia-dr3/blob/master/settings.py
.venv/bin/iop --migrate https://github.com/grongierisc/iris-gaia-dr3/blob/master/settings.py --dry-run
Full benchmark check:
./RunChallenge.sh > /tmp/gaia-results.csv
wc -l /tmp/gaia-results.csv
On the current implementation, the full run produces 57099 data rows for the benchmark dataset, plus the header row.
Last checked by moderator
13 Jul, 2026WorksMade with
Version
1.0.003 Jul, 2026
Category
Works with
InterSystems IRISFirst published
03 Jul, 2026Last edited
03 Jul, 2026