© 2026 InterSystems Corporation, Cambridge, MA. All rights reserved.Privacy & TermsGuaranteeSection 508Contest Terms

iris-speed-test 

5
1 reviews
0
Awards
4.2k
Views
0
IPM installs
 0
0 8
8
Details
Releases (8)
Reviews (1)
Issues
Show how fast InterSystems IRIS is compared to other competitors
What's new in this version
- Updated all databases to latest versions: IRIS 2026.1, PostgreSQL 18, MySQL 9.7.0, SQL Server 2025
- Refreshed benchmark results with new performance comparisons
- Fixed docker-compose worker auto-registration and startup issues
Hybrid Transactional-Analytical Processing (HTAP) Demo
Update: This benchmark uses the latest database versions including InterSystems IRIS Community 2026.1, PostgreSQL 18, MySQL 9.7.0, and SQL Server 2025.
The capability to ingest thousands or millions of records per second while allowing for simultaneous queries in real time is required by many use cases across multiple industries, e.g. equity trade processing, fraud detection, IoT applications including anomaly detection and real time OEE, etc. Gartner calls this capability “HTAP” (Hybrid Transactional Analytical Processing). Others such as Forrester call it Translytics. InterSystems IRIS is a powerful, scalable, high performance and resource efficient transactional-analytic data platform that provides the performance of in-memory databases with the consistency, availability, reliability and lower costs of traditional databases.
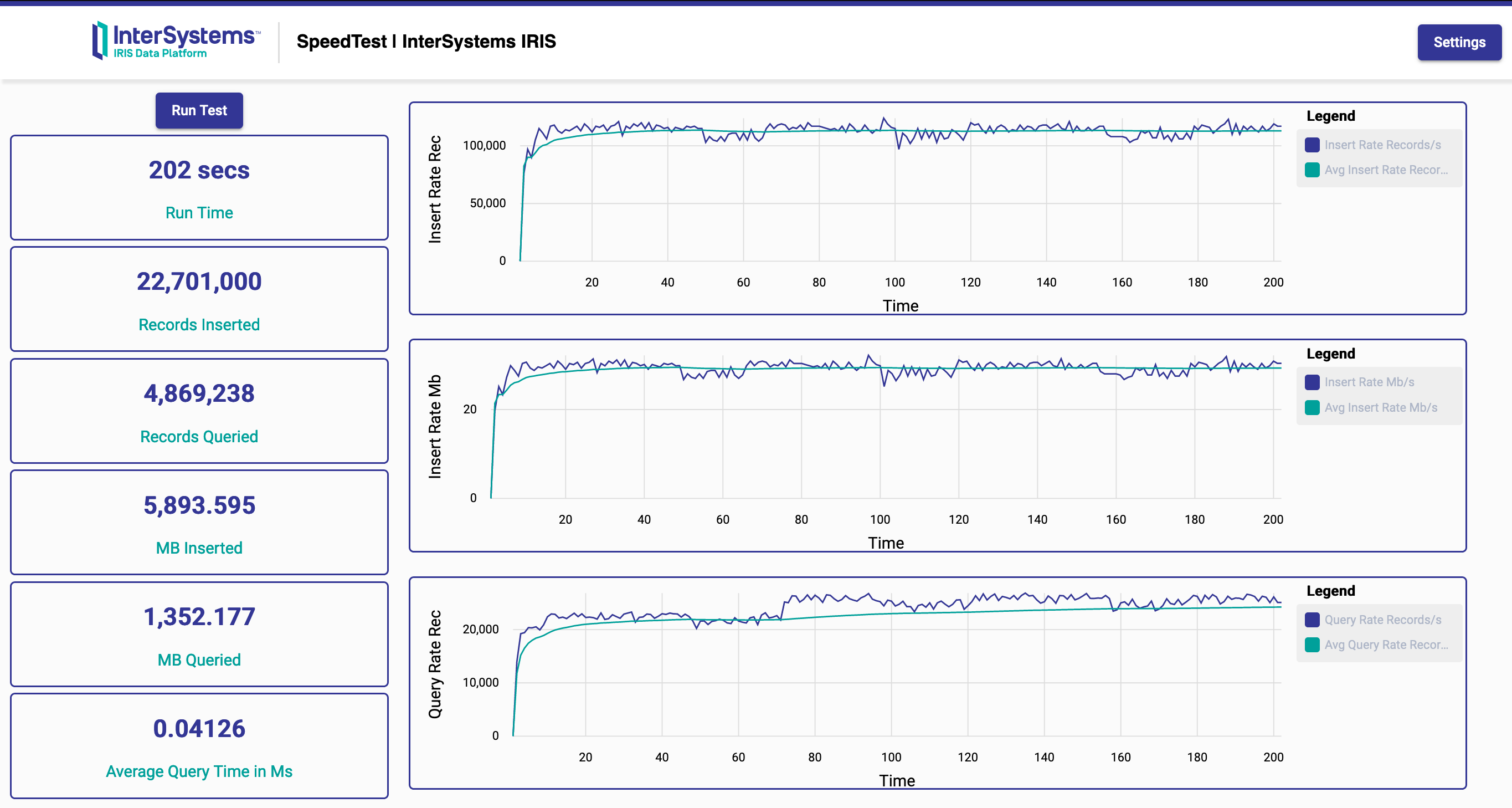
This demo shows how InterSystems IRIS can ingest thousands of records per second while allowing for simultaneous queries on the data on the same cluster with very high performance for both ingestion and querying, and with low resource utilization. The demo works on a single InterSystems IRIS instance or on an InterSystems IRIS cluster on the cloud.
The same demo can be run on PostgreSQL, MySQL, and SQL Server to compare performance and resource utilization in “apples-to-apples” comparisons.
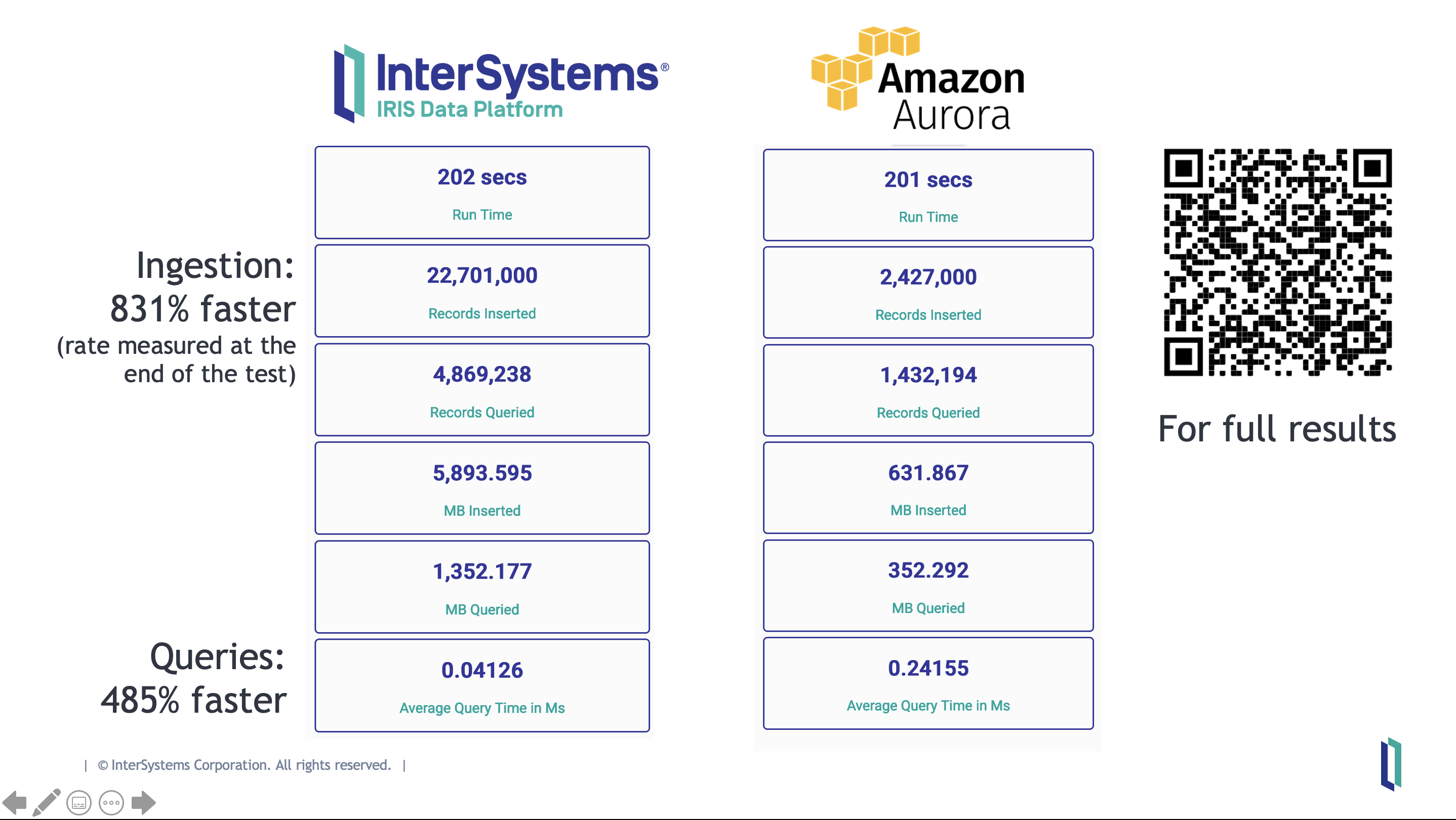
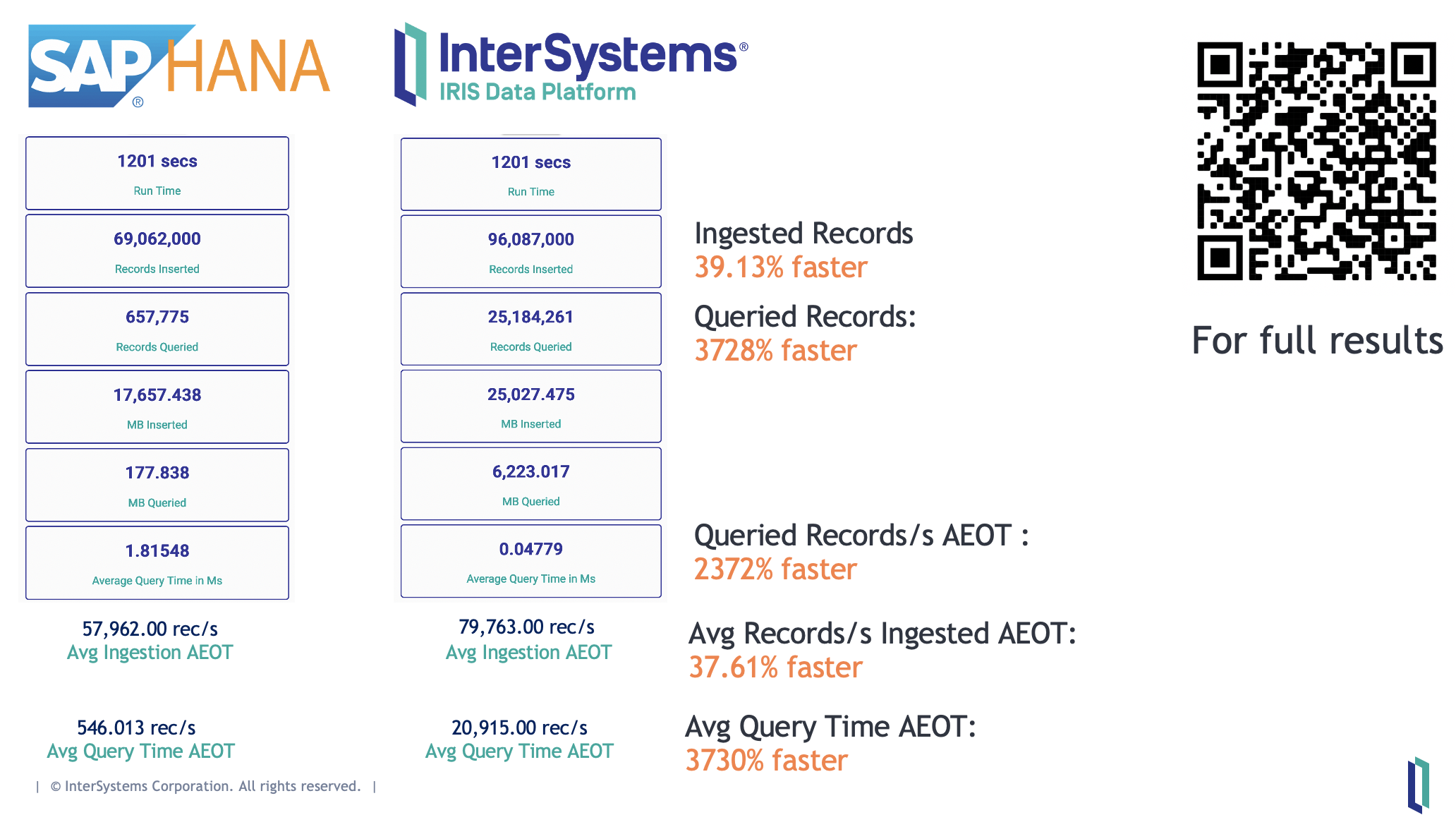
You can run the tests on both your own PC and AWS! Here are some results:
-
InterSystems IRIS x PostgreSQL 18
- InterSystems IRIS ingests 76.7% more records than PostgreSQL 18
- InterSystems IRIS is 23.7% faster than PostgreSQL 18 at querying
-
InterSystems IRIS x MySQL 9.7.0
- InterSystems IRIS ingests 936% more records than MySQL 9.7.0
- InterSystems IRIS is 213% faster than MySQL 9.7.0 at querying
-
InterSystems IRIS x SQL Server 2025
- InterSystems IRIS ingests 369% more records than SQL Server 2025
- InterSystems IRIS is 37,545% faster than SQL Server 2025 at querying
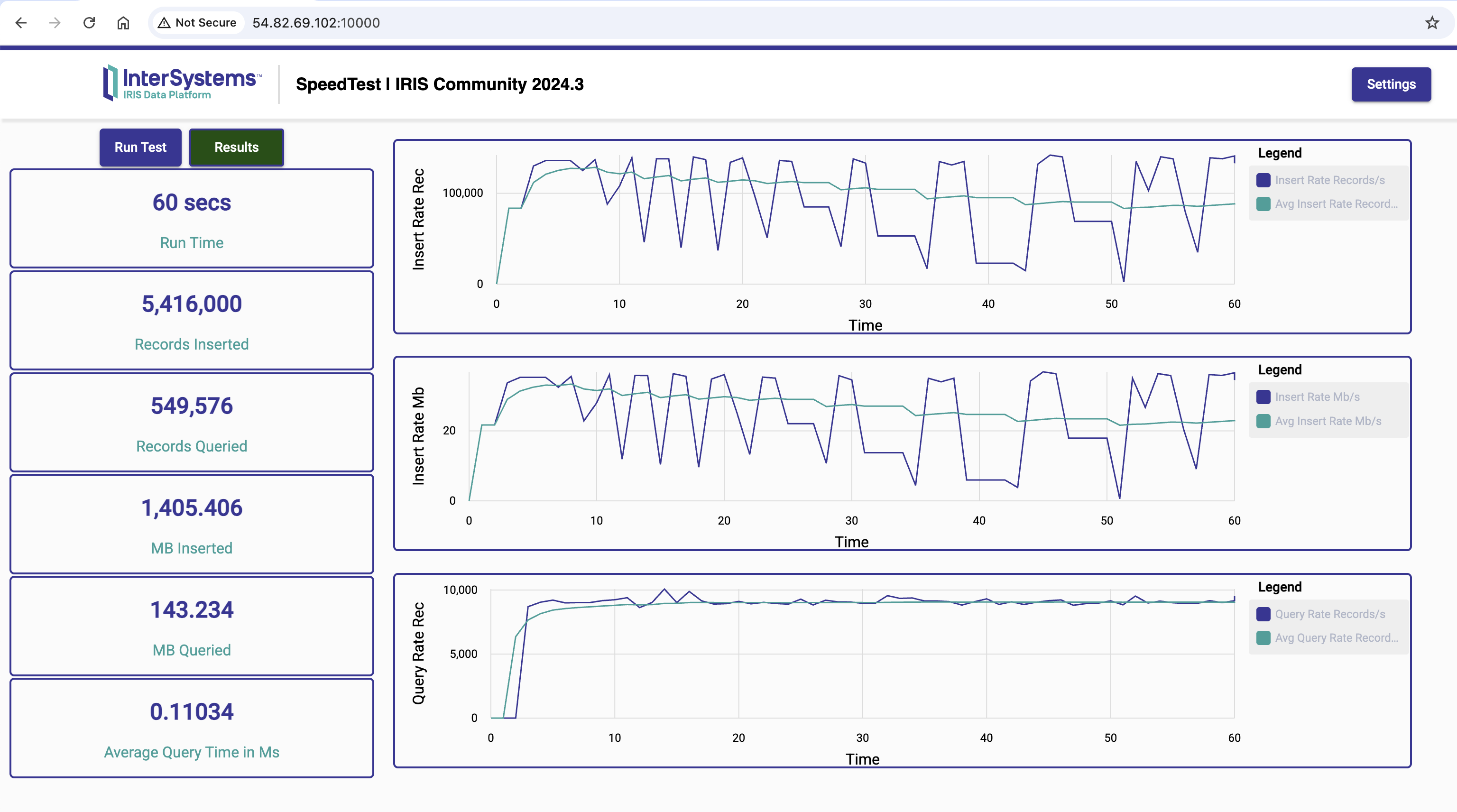
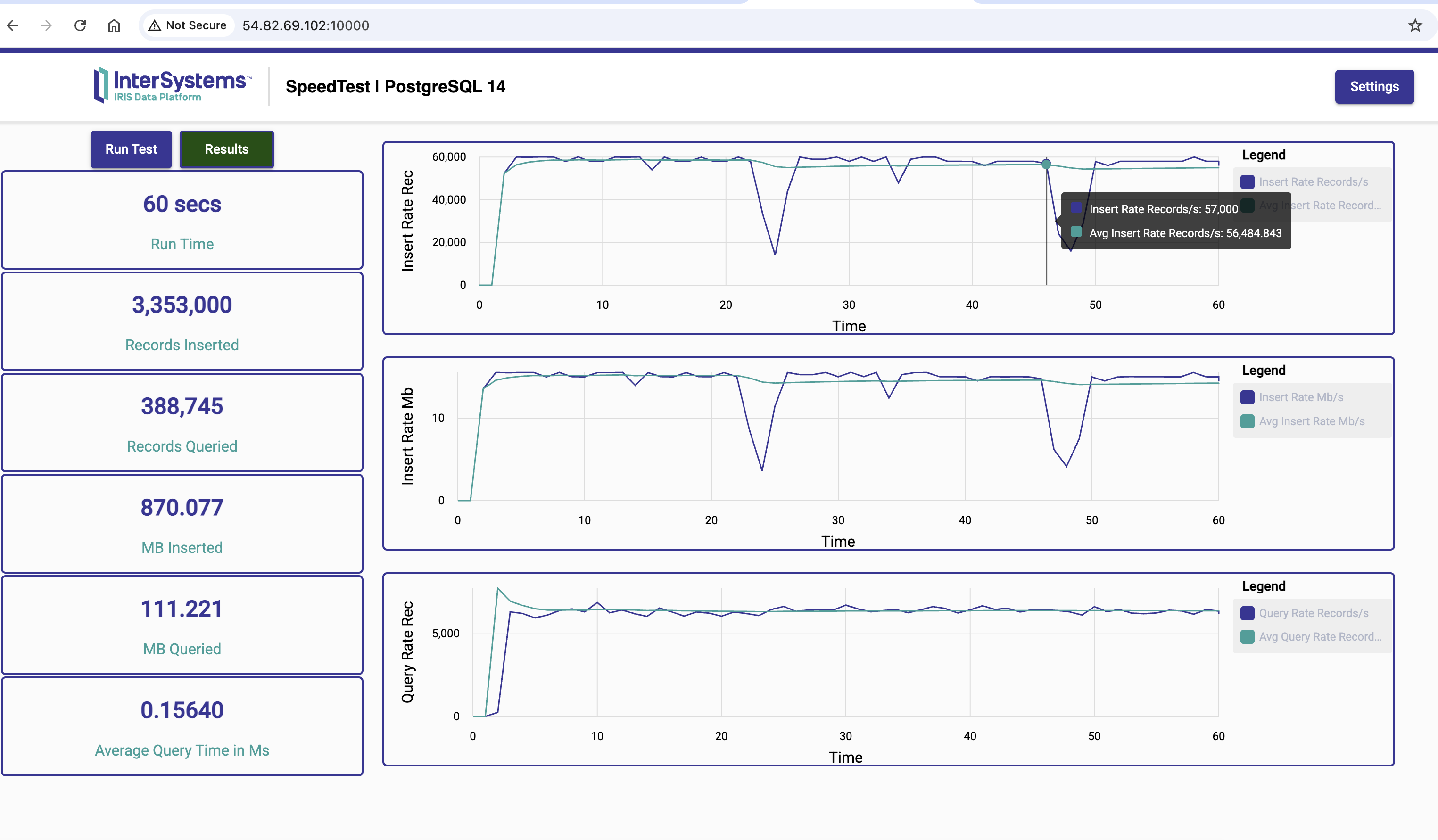
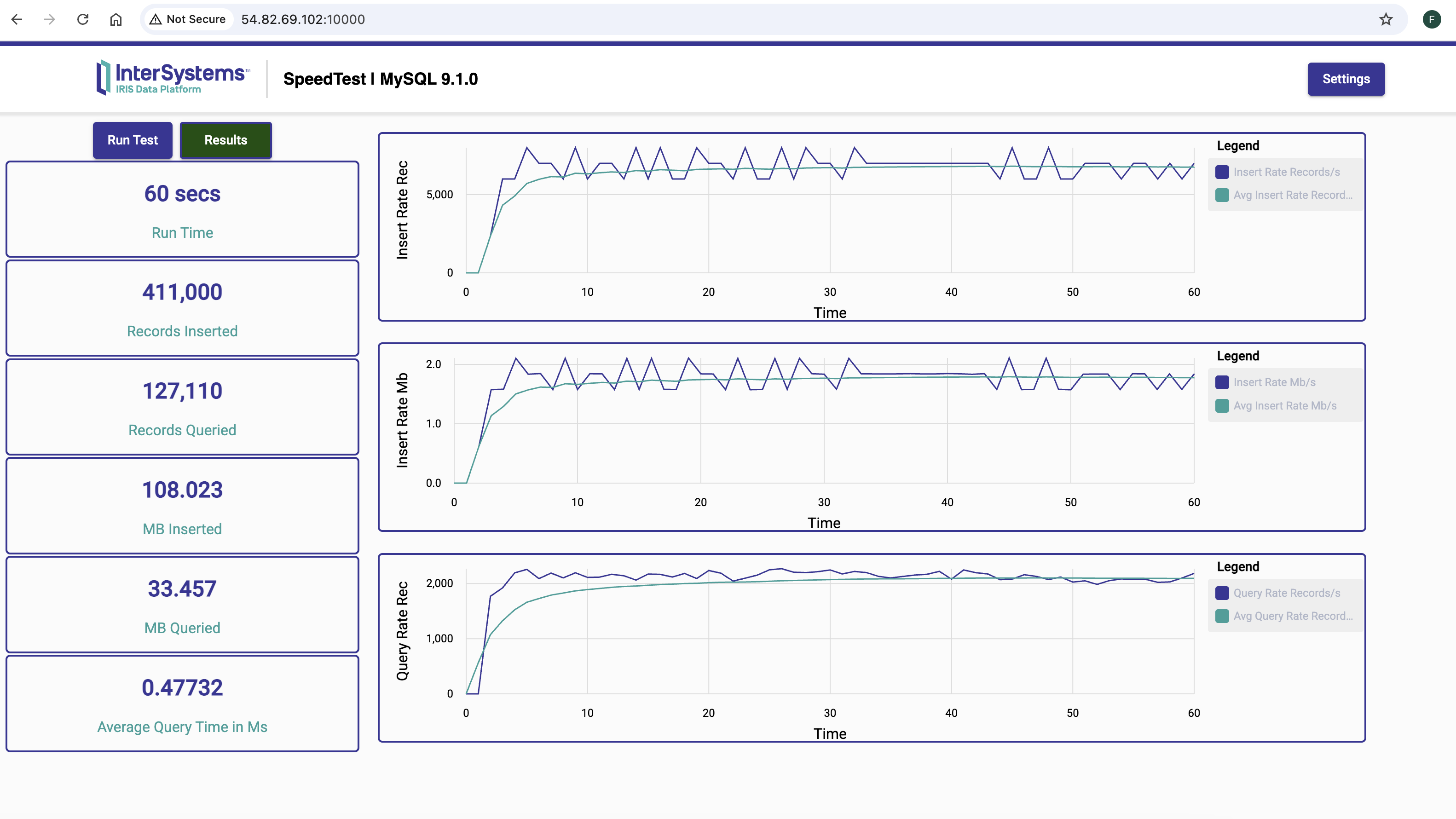
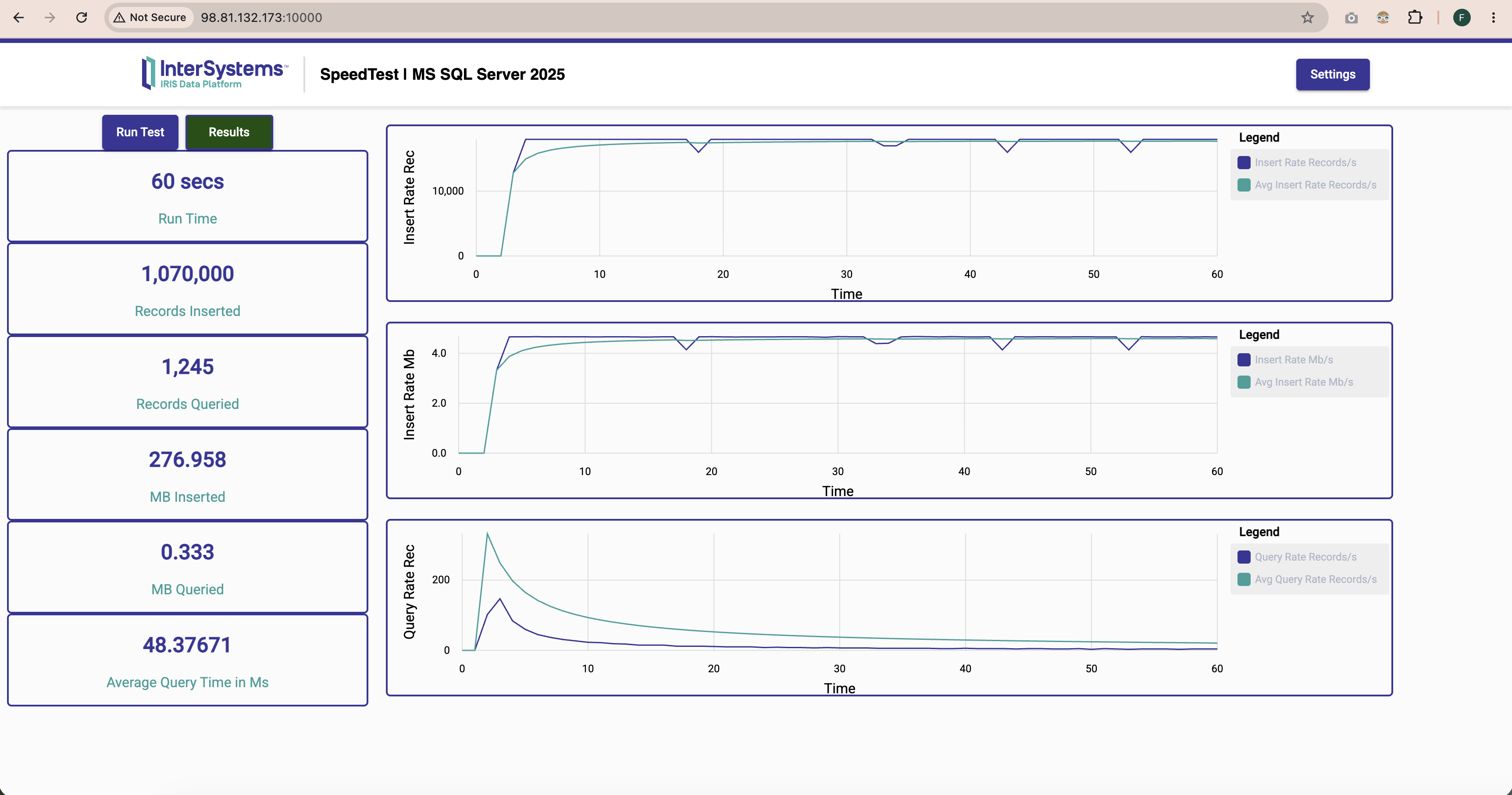
1 - Running the Speed Test on AWS
Follow this link to see instructions on how to run this Speed Test on AWS comparing InterSystems IRIS with other databases.
2 - How to run it on your PC
The pre-requisites for running the speed test on your PC are:
- Docker and Docker Compose
- Git - If you want to run all the the tests on your PC or in AWS. If you just want to run the test with InterSystems IRIS, you may not need git.
You can currently run this demo on your PC with InterSystems IRIS, PostgreSQL, MySQL, and SQL Server.
2.1 - Run it with InterSystems IRIS Community
To run the demo on your PC, make sure you have Docker installed on your machine.
You can quickly get it up and running with the following commands on your Mac or Linux PC:
wget https://raw.githubusercontent.com/fanji-isc/IRIS-Speed-Test/refs/heads/main/docker-compose.yml
docker-compose up
If you are running on Windows, download the docker-compose.yml file to a folder. Open a command prompt and change to that folder. Then type:
c:\MyFolder\docker-compose up
You can clone this repository to your local machine using git to get the entire source code. You will need git installed and you would need to be on your git folder:
git clone https://github.com/fanji-isc/IRIS-Speed-Test
cd IRIS-Speed-Test
docker-compose up
When starting, you will see lots of messages from all the containers that are starting. That is fine. Don’t worry!
When it is done, it will just hang there, without returning control to you. That is fine too. Just leave this window open. If you CTRL+C on this window, docker compose will stop all the containers and stop the demo.
After all the containers have started, open a browser at http://localhost:10000 to see the demo UI.
Just click on the Run Test button to run the HTAP Demo! It will run for a maximum time of 300 seconds or until you manually stop it.
If you want to change the maximum time to run the test, click the Settings button at the top right of the UI. Change the maximum time to run the speed test to whatever you want.
After clicking on Run Test, it should immediately change to Starting…. If you are testing InterSystems IRIS or SQL Server, it may stay on this status for a long time since we are pre-expanding the database to its full capacity before starting the test (something that we would normally do on any production system). InterSystems IRIS is a hybrid database (In Memory performance with all the benefits of traditional databases). So InterSystems IRIS still needs to have its disk database properly expanded. Just wait for it. For some databases, we could not find a way of doing this right from start (Aurora and MySQL) so what we did was to run the Speed Test once to “warm it up”. Then we run it again (which causes the table to be truncated) with the database warmed up.
Warning: InterSystems IRIS Database expansion can take some time. Fortunately, when running on your PC, we will pre-expand the database only to up to 9Gb since InterSystems IRIS Community has a limit on the database size.
When the test finishes running, a green button will appear, allowing you to download the test results statistics as a CSV file.
When you are done testing, go back to that terminal and enter CTRL+C. You may also want to enter with the following commands to stop containers that may still be running and remove them:
docker-compose stop
docker-compose rm
This is important, especially if you are going back and forth between running the speed test on one database (say InterSystems IRIS) and some other (say MySQL).
2.2 - MySQL on your PC
To run this demo against MySQL:
wget https://raw.githubusercontent.com/fanji-isc/IRIS-Speed-Test/refs/heads/main/docker-compose-mysql.yml
docker-compose -f ./docker-compose-mysql.yml up
Now, we are downloading a different docker-compose yml file; one that has the mysql suffix on it. And we must use -f option with the docker-compose command to use this file. As before, leave this terminal window open and open a browser at http://localhost:10000.
When you are done running the demo, go back to this terminal and enter CTRL+C. You may also want to enter with the following commands to stop containers that may still be running and remove them:
docker-compose -f ./docker-compose-mysql.yml stop
docker-compose -f ./docker-compose-mysql.yml rm
This is important, especially if you are going back and forth between running the speed test on one database (say InterSystems IRIS) and some other.
2.3 - SQL Server 2025 on your PC
To run this demo against SQL Server:
wget https://raw.githubusercontent.com/fanji-isc/IRIS-Speed-Test/refs/heads/main/docker-compose-sqlserver.yml
docker-compose -f ./docker-compose-sqlserver.yml up
As before, leave this terminal window open and open a browser at http://localhost:10000.
2.4 - PostgreSQL on your PC
To run this demo against PostgreSQL:
wget https://raw.githubusercontent.com/fanji-isc/IRIS-Speed-Test/refs/heads/main/docker-compose-postgres.yml
docker-compose -f ./docker-compose-postgres.yml up
As before, leave this terminal window open and open a browser at http://localhost:10000.
3 - Resources
A video about this demo is in the works! In the meantime, here is an interesting article that talks about InterSystems IRIS architecture and what makes it faster.
Common Questions and Answers
For answers to frequently asked questions about InterSystems IRIS and other related topics, check out our Common Questions and Answers.
Last checked by moderator
02 May, 2026WorksMade with
Version
4.0.008 Jun, 2026
Ideas to the app
Category
Works with
InterSystems IRISInterSystems IRIS for HealthFirst published
03 Dec, 2019Last edited
08 Jun, 2026