

© 2026 InterSystems Corporation, Cambridge, MA. All rights reserved.Privacy & TermsGuaranteeSection 508Contest Terms

ESKLP 

4.5
1 reviews
2
Awards
899
Views
0
IPM installs
 0
0 4
4
Details
Releases (6)
Reviews (1)
Awards (2)
Issues
Videos (1)
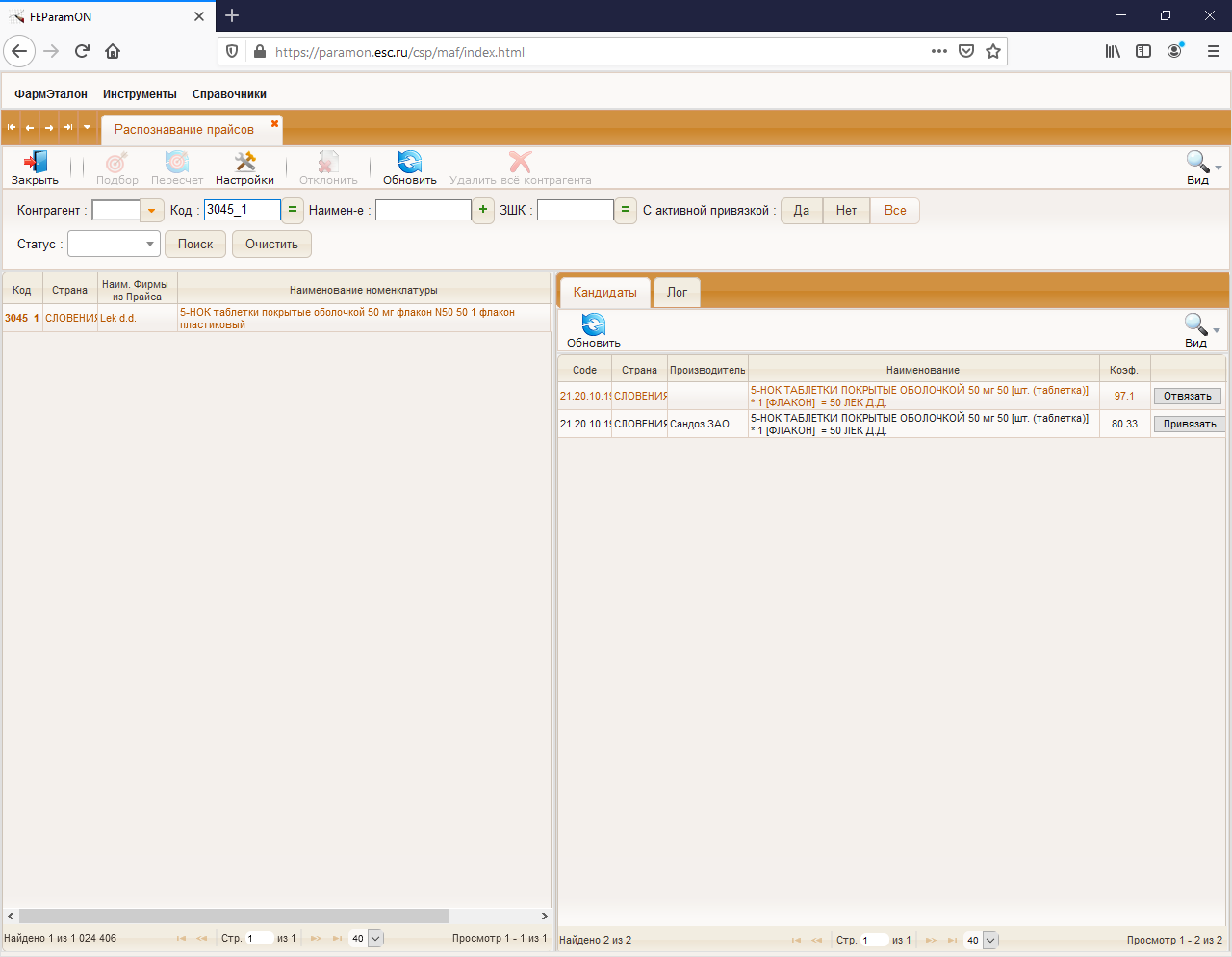
Looks very complete
- There is a clean build of the Docker image starting without problem
- The description looks good and also the related productions work well
- the demo is quite impressive if you understand that you have to use
- гостевой вход >>> (guest entrance) for logon and not OK.
- and that Инструменты / Распознавание >>> (Tools / Recognition )
- is the menu tree to use (not Username / PW as I assumed).
- I missed some guide on how to verify operation interactively.
Last checked by moderator
14 Nov, 2025Doesn't workMade with
Version
1.0.523 Oct, 2021
Ideas to the app
Category
Works with
InterSystems IRISFirst published
12 Jul, 2020Last edited
04 Jun, 2022