© 2026 InterSystems Corporation, Cambridge, MA. All rights reserved.Privacy & TermsGuaranteeSection 508Contest Terms

ESKLP  Issue Detected
Issue Detected

4.5
1 reviews
2
Awards
885
Views
0
IPM installs
 0
0 4
4
Details
Releases (6)
Reviews (1)
Awards (2)
Issues
Videos (1)
Application demonstrates using Python and InterSystems IRIS to resolve linear regression in task of checking similarity of two text strings
What's new in this version
- Fast creating web-applications, every form is described in simple JSON;
- Integrated import/export *.xlsx for persistent classes, which Extends (%Persistent, Lib.Abstract.StorableTables);
- User rights management to control view and use form components;
- Creating users and change passwords in application (for cases when you need some administration without portal;
- Server monitoring with email of troubles;
- Interface translate option;
- Reports of user's actions.
Application demonstrates using Python and InterSystems IRIS to resolve
linear regression in task of checking similarity of two text strings. Strings contain descriptions of some goods.
Problem: To get an analogue of directory B for the nomenclature of
directory A automatically. For example, price list of some pharmacy
company and some dictionary, Like ESKLP (federal single structured
reference directory of drugs in Russia).
This example is available at https://paramon.esc.ru/csp/maf/index.html
in guest mode (Choose: Инструменты / Распознавание )
 {width=“6.496527777777778in”
{width=“6.496527777777778in”
height=“5.045138888888889in”}
Input data:
-
Price list (left part on screen),
-
Some dictionary (ESKLP for example)
-
Sorted by similarity candidates from ESKLP for every string from
price list: many candidates to one position from price list. -
Information about every pair “Price list – candidate ESKLP”
Similarity is a classic linear regression function, where we calculate
metrics values from two strings, and if the full value of function is
the same more, then minimum we want – then we can say that positions
are the same.
Metrics:
-
Country - similarity of Country;
-
Decimal - similarity of two number list, especially prepared;
-
LekForm - similarity of dosage form, especially prepared;
-
ManufName - similarity of manufacturer's name;
-
Ngramm - similarity of two strings by n-gramm method;
-
Nomer - similarity of tablet's count in pack;
-
ProdName - similarity of production name;
-
Simber - similarity of two number list, especially prepared;
-
Translit - similarity of two strings in translit;
-
Trigram - similarity of two strings in translit by n-gramm method;
-
BarcodeSimilarity (new) - similarity of two strings that contain (o not) barcodes
Some of these metrics getting-values-methods are shown in
App.MAF.Metric.
Information about every pair: is collected in App_MAF.LinkML, it
contains:
-
Code from organization’s nomenclature dictionary
-
ESKLP-code (federal single structured reference directory of drugs
in Russia) -
Similarity value
-
Each of metric values.
-
Every link marked by human - if this link right or not.
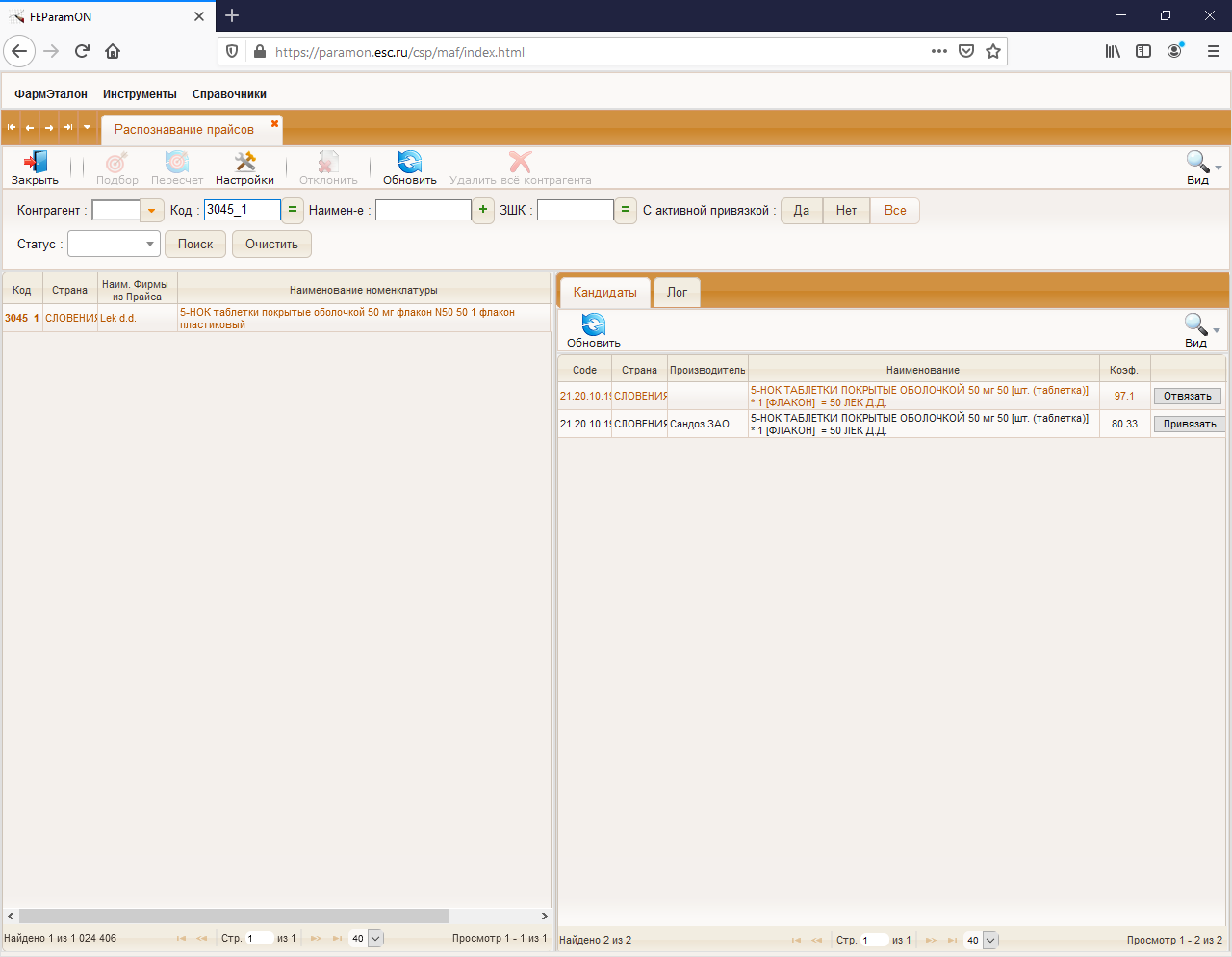
At start all weights of all metrics = 1. And for example from print
screen (code = 3045_1 )the final value of candidates are 96.38 and 95.5.
The second candidate (95.5) is wrong, but the difference is not very
big.
Solution
Get weights of all metrics, because some of them are not so effective to
make our choice: if string from our organization’s dictionary and string
from ESKLP are the same or not. And when we will compare another
organization’s nomenclature, there will be much less error.
-
Reset coefficients: in terminal d ##class(App.MAF.Plan).ResetMetricsWeights(1)
-
Start production: ( Interoperability > Configure > Production
Configuration > Category: Match)
ml.match.RgrCoefProcess ->Start button -
Test Production: ml.match.RgrCoefProcess > Actions > Test button
-
Choose “Ens.Request” in Request Type and press button “Invoke Testing Service”. Please wait for finish.
-
Get result, see column “weight”: (IRIS-Management Portal: System >
SQL)
SELECT m.id AS metricId, link.weight, link.id AS linkId, link.Order AS
Ord FROM App_MAF.Plan plan LEFT JOIN app_maf.PlanMetric link ON plan.id
= link.plan RIGHT JOIN app_maf.Metric m ON link.Metric = m.id WHERE
plan.id = 1 AND link.active = 1 ORDER BY Ord
Now we have anover values of weight for every metric. Why it’s good: one metric began to express the similarity of strings more than another, and we could see another values of similarity function for different types of goods. For example - barcode for computer goods is less important, than for medicaments, and weight for BarcodeSimilarity metric when checking computer goods must be less then value for it’s metric, when we check similarity of two strings containig description of medicaments goods.
So, we could save different plans of checking similarity for different types of goods.
In the new version added calculation of logistic regression to compare with linear regression model. How it works:
- At first we train our model on marked data;
- Then we send the same data to trained model;
- Get and save result (1 - the same goods, or 0 - different goods described in 2 strings) for every pair of strings in new-created field “LinkedLogReg” of “App.MAF.LinkML”-class.
We could see big difference between precisions of linear regression model and logistic regression model.
Working with web-application (code of web-application is not presented in this repository yet)
- Go to https://paramon.esc.ru/csp/maf/index.html, press Guest mode;
- Open in menu «Распознавание прайсов» (Меню : / Инструменты / Распознавание);
- Filter positions by choosing Contragent by code “FE”;
- Press button “Настройки”;
- Choose Check-Plan Лексредства V2, choose “App.SPR.ESCLP” as source for analogs. Do not choose contragent in this options. Press OK;
- You could see nomenclature of organisation in left table and analogs for every position in right table with value of resul coefficienе, which means how two positions are similar.
Made with
Version
1.0.523 Oct, 2021
Ideas portal
Category
Works with
InterSystems IRISFirst published
12 Jul, 2020Last edited
04 Jun, 2022Last checked by moderator
14 Nov, 2025Doesn't work